
By William Yang
Introduction
Recent powerful text-to-image (T2I) models, such as Stable Diffusion, are very capable of generating diverse and realistic images. While they are commonly used for creating creative edits of images, a natural question arises: Can we use these powerful models as a tool to create a synthetic dataset used to train downstream classification models? Using T2I models would alleviate the need to collect and label thousands of real images – one could simply prompt a T2I model like Stable Diffusion with class names.

However, while T2I models excel at producing visually appealing imagery, they often fail to generate the subtle features that define fine-grained categories, such as Boeing 747-300 vs. 747-400. (Comparisons between real and generated images are shown in Figure 1.) In other words, to the human eye, the synthetic samples might look reasonable, but they actually lack the distinctions necessary for tasks such as differentiating between bird species, aircraft variants, or car models.
The Problem: Synthetic Data Overfits to the Limited Data
To adapt a T2I model to generate images for a specific classification task, practitioners typically fine-tune it on a few real examples for each class. This is because without fine-tuning, generated images often have artifacts or semantic mismatches, lacking the necessary discriminative cues. While fine-tuning can improve class fidelity, it introduces a drawback: The model can overfit to the small dataset, memorizing particularities of specific examples, harming diversity.
Overfitting is particularly damaging because it can easily form unintended associations between classes. For example, if every image of a “DHC-6 aircraft” in the training set happens to show water in the background, the model might only generate DHC-6 aircrafts with a water background.
The Solution: Introduce Context Into Fine-tuning
We introduce the method BeyondOBjects (BOB). Our approach builds on a simple insight: Context matters for controllability during both fine-tuning and generation. The key innovation in BOB lies in its two-stage process:
- Context preservation during fine-tuning (step 1 and 2 of Fig. 2). Capture and encode background and pose information, what we refer to as context attributes, in text prompts so that the T2I model learns a disentangled, detailed one-to-one mapping between the text descriptions and the images.
- Context marginalization during generation (step 3 and 4 of Fig. 2). Randomly sample these context attributes (background, pose) across all classes when generating new images, thereby breaking spurious class-context links.
By modeling background and pose as explicit variables, BOB prevents T2I models from overfitting and generating spurious correlations that undermine synthetic data for image classification.
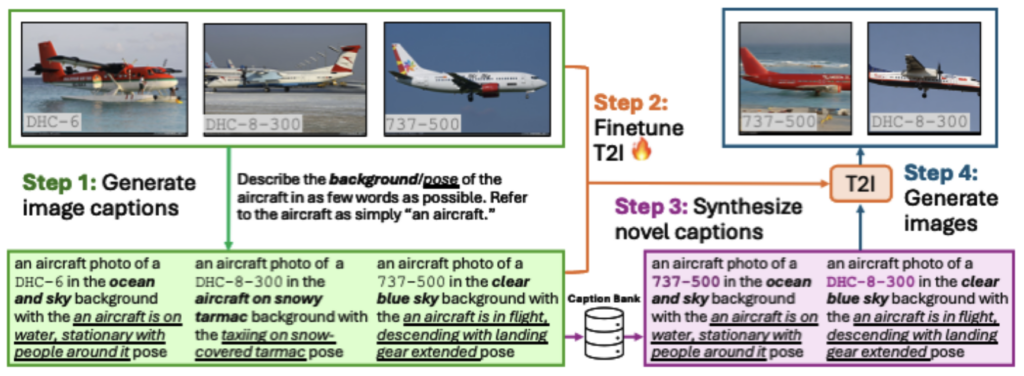
Stage 1: Context preservation during fine-tuning
A few-shot dataset contains rich scene information, but typical fine-tuning prompts are not descriptive enough to retain this rich information. A caption such as “a photo of a Boeing 737-500” collapses all the varied backgrounds and poses into a single coarse description. This forces the T2I model to infer missing details and encourages overfitting to whatever limited variation appears in the few examples.
BOB addresses this by extracting structured, class-agnostic context attributes from each training image using the Qwen 2.5-VL captioning model to create a new and more descriptive caption. Concretely, for every image, BOB captures:
- Background (e.g., “clear blue sky,” “snowy tarmac,” “over open water”)
- Pose (e.g., “in flight,” “parked at the gate,” “on water, stationary”)
These attributes are then woven into structured prompts of the form:
“A photo of a [classname] in the [background] background with the [pose] pose.”
During fine-tuning, the T2I model learns a clear, disentangled mapping between text and image, preserving the diversity of scene configurations found in the real data. This step prevents collapse while maintaining controllability.
Stage 2: Context Marginalization during generation
Once the T2I learns the clear, disentangled mapping from fine-tuning, we marginalize out the class-agnostic context attributes during generation. In few-shot datasets, certain contexts may appear exclusively with certain labels, leading the model to learn spurious correlations. BOB breaks this dependency by randomizing context at generation time. All background–pose pairs extracted during Stage 1 are stored in the caption bank. When generating synthetic samples, BOB samples these context attributes uniformly across all classes. More concretely, given classname CLS, a random background [BKG], and a random pose [PS], the T2I model then generates images using the caption:
“A photo of a [CLS] in the [BKG] background with the [PS] pose.”
This effectively marginalizes background and pose. The result is a synthetic dataset that is both realistic and diverse, free from class-context entanglement.
Results Using BOB-generated Images for Few-Shot Image Classification
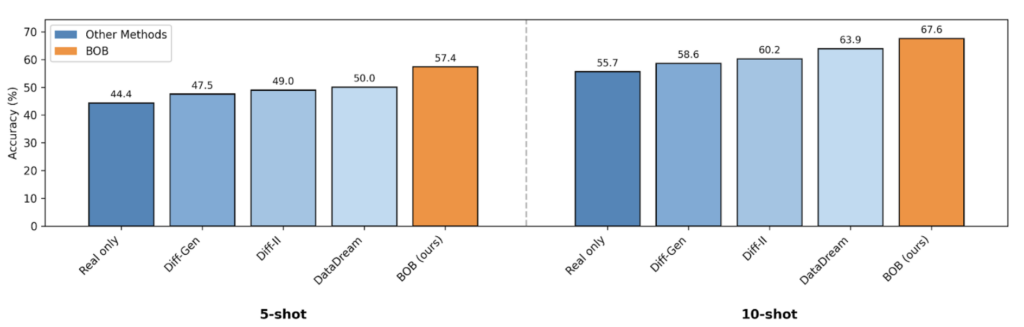
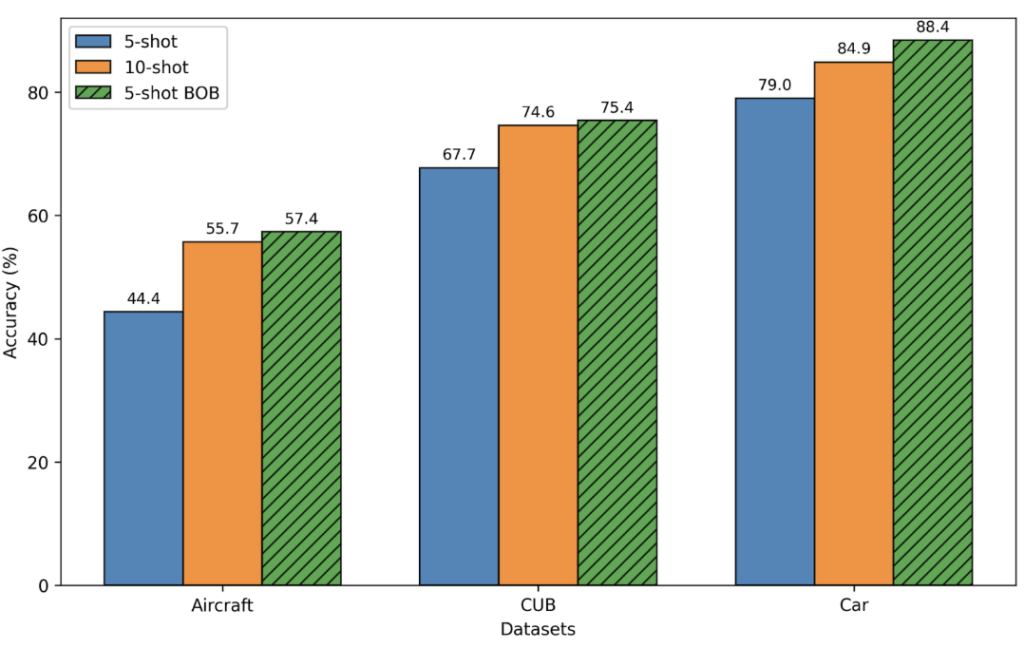
A central question in synthetic data research is whether a generative model can provide enough semantic fidelity and intra-class diversity to meaningfully improve downstream classifiers when only a handful of real samples are available. BOB delivers consistent gains across this setting, outperforming previous approaches under both 5-shot and 10-shot regimes. We show in Figure 3 and 4:
- On the aircraft dataset, BOB boosts accuracy from 44.4% → 57.4% in a 5-shot classification setting (Fig. 3 left) and from 55.7% → 67.6% in 10-shot (Fig. 3 right), exceeding all prior diffusion-based methods.
- Across multiple datasets of objects like planes (Aircraft), birds (CUB), and cars (Cars), BOB’s 5-shot performance matches or surpasses the 10-shot real-only baseline (Fig. 4), showing that high-quality synthetic data can lead classification models to match the performance when using a greater number of real images.
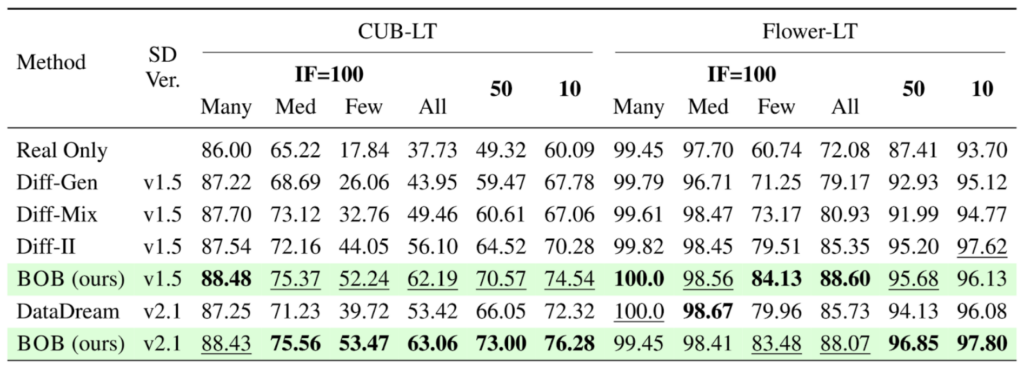
Long-tail Classification Results
BOB’s advantages extend beyond the few-shot setting and remain strong under long-tail class distributions, where many categories have very few real examples. Long-tail scenarios are difficult for generative augmentation because models tend to overfit common classes and fail to learn the subtle cues that distinguish visually similar but infrequent categories. By disentangling class identity from background and pose, BOB generates more balanced and discriminative samples across all frequency levels.
- The long-tail versions of CUB and Flowers dataset is composed of 200 bird and 102 flower classes respectively where the number of images for each class is artificially skewed (controlled by the imbalance factor) to create a long-tail distribution. On these datasets shown in Table 1, BOB consistently improves overall accuracy, with especially large gains on the rarest classes.
- For CUB-LT with the largest skew (imbalance factor 100), BOB boosts tail-class accuracy from 44.05% → 52.24%, outperforming previous T2I-based augmentation methods.
- Surprisingly on top of tail classes, BOB also improves classification performance on head classes, indicating that BOB improves even on classes with ample amount of data
Where is the Performance Improvement Coming From?
1. Better alignment with the real image distribution. Per-class Fréchet Inception Distance (FID) is a measure of distribution similarity where lower value indicates more similar distribution. BOB’s generated images have a lower average per-class FID, meaning that its images are closer to the real data distribution: average per-class FID ≈ 26 (BOB) vs. 31 (DataDream) vs. 37 (Diff-II). Visually, BOB-generated aircraft exhibit greater diversity while still looking realistic (Fig. 5).

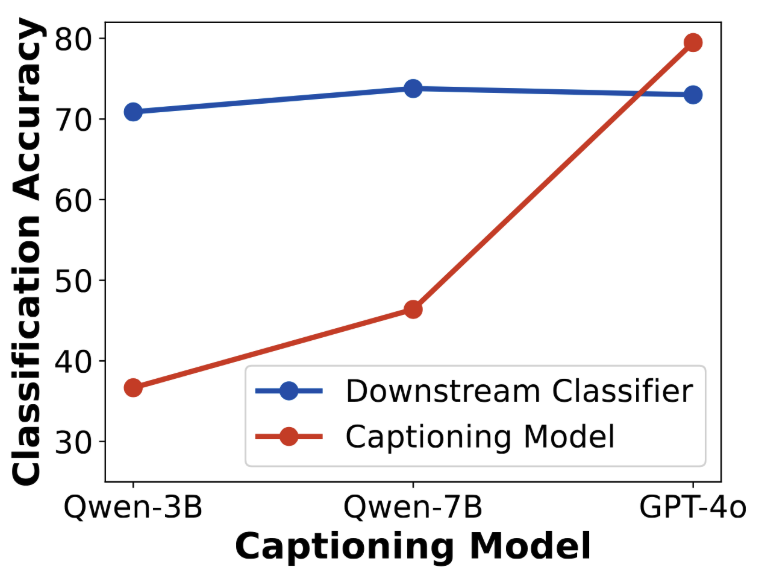
2. Improvement is not from caption model leakage. One might suspect that the captioning model (Qwen-VL or GPT-4o) injects classification knowledge into the generation pipeline. However, we find no correlation between captioner classification accuracy and downstream classifier performance (Fig. 6). Even weaker captioners (Qwen-3B) yield comparable gains. The benefits are not from hidden supervision.
3. Both stages matter. An ablation study shown in Table 2 confirms the necessity of both context preservation and marginalization. We observe that using only context preservation and marginalization achieves 70.13% and 65.90% accuracy respectively, but incorporating both in conjunction results in the best accuracy of 73.78%.
| Configuration | Accuracy |
| No preservation or marginalization (DataDream baseline) | 68.00% |
| Marginalization only | 70.13% |
| Preservation only | 65.90% |
| Both (BOB) | 73.78% |
Conclusion
Our method, BeyondOBjects (BOB) provides a straightforward and effective strategy for improving synthetic data used in fine-grained classification. By preserving the background and pose of images used when fine-tuning a T2I model, and then randomizing background and pose when generating novel samples, images generated by BOB can be used to fine-tune better image classification models. Additional ablations demonstrate that BOB reduces unintended class associations and increases both fidelity and diversity in the generated samples. This work highlights the potential of caption-guided fine-tuning to improve synthetic data quality for downstream classification tasks and opens avenues for further research on scaling this approach to broader domains and modalities.
This paper was accepted by CVPR 2026. To learn more about BOB, the full paper is available on ArXiv and code on Github.
Leave a Reply